Analyzing TED Talks
This article is a part of a series intended to show how to use Memgraph on real-world data to retrieve some interesting and useful information.
We highly recommend checking out the other articles from this series which are listed in our tutorial overview section.
Introduction
TED is a nonprofit organization devoted to spreading ideas, usually in the form of short, powerful talks. Today, TED talks are influential videos from expert speakers on almost all topics — from science to business to global issues. Here we present a small dataset which consists of 97 talks, show how to model this data as a graph and demonstrate a few example queries.
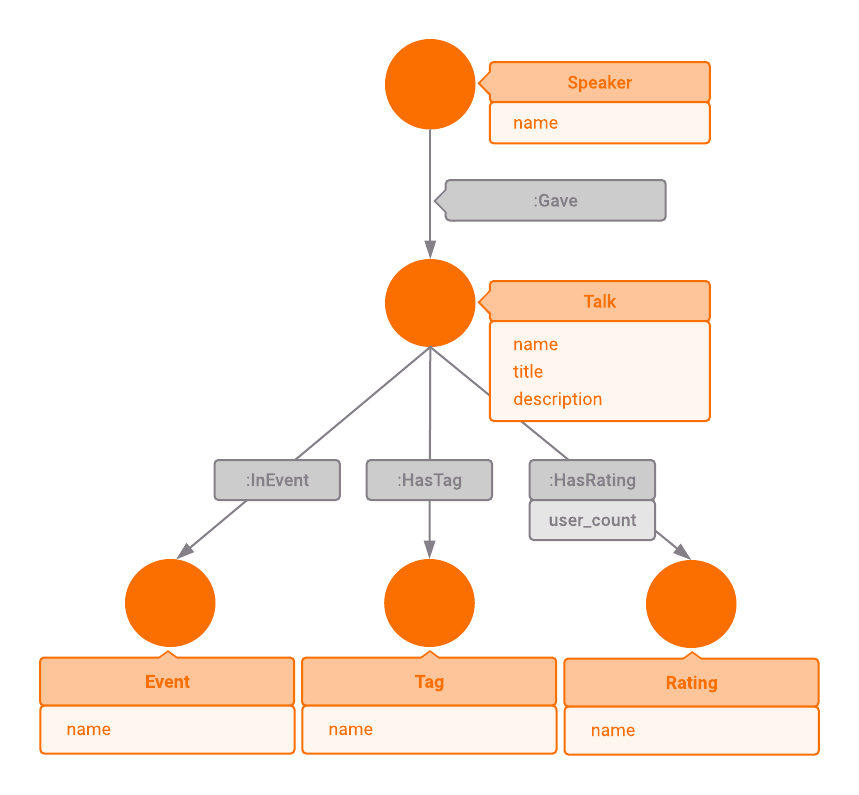
Data Model
- Each TED talk has a main speaker, so we
identify two types of nodes —
TalkandSpeaker. - We add an edge of type
Gavepointing to aTalkfrom its mainSpeaker. - Each speaker has a name so we can add property
nametoSpeakernode. - We'll add properties
name,titleanddescriptionto nodeTalk. - Each talk is given in a specific TED event, so we can
create node
Eventwith propertynameand relationshipInEventbetween talk and event. - Talks are tagged with keywords to facilitate searching, hence we
add node
Tagwith propertynameand relationshipHasTagbetween talk and tag. - Users give ratings to each talk by selecting up to three
predefined string values. Therefore we add node
Ratingwith these values as propertynameand relationshipHasRatingwith propertyuser_countbetween talk and rating nodes.
Exploring the dataset
You have two options for exploring this dataset.
If you just want to take a look at the dataset and try out a few queries, open
Memgraph Playground and continue with
the tutorial there. Note that you will not be able to execute write operations.
On the other hand, if you would like to add changes to the dataset, download the
Memgraph Lab desktop application and navigate
to the Datasets tab in the sidebar. From there, choose the dataset
TED talks and continue with the tutorial.
Example queries using Cypher
In the queries below, we are using Cypher to query Memgraph via the console.
1) Find all talks given by specific speaker:
MATCH (n:Speaker {name: "Hans Rosling"})-[:Gave]->(m:Talk)
RETURN m.title;
2) Find the top 20 speakers with most talks given:
MATCH (n:Speaker)-[:Gave]->(m)
RETURN n.name, count(m) AS talksGiven
ORDER BY talksGiven
DESC LIMIT 20;
3) Find talks related by tag to specific talk and count them:
MATCH (n:Talk {name: "Michael Green: Why we should build wooden skyscrapers"})
-[:HasTag]->(t:Tag)<-[:HasTag]-(m:Talk)
WITH *
ORDER BY m.name
RETURN t.name, collect(m.name) AS names, count(m) AS talksCount
ORDER BY talksCount DESC;
4) Find 20 most frequently used tags:
MATCH (t:Tag)<-[:HasTag]-(n:Talk)
RETURN t.name AS tag, count(n) AS talksCount
ORDER BY talksCount DESC, tag
LIMIT 20;
5) Find 20 talks most rated as "Funny". If you want to query by other ratings, possible values are: Obnoxious, Jaw-dropping, OK, Persuasive, Beautiful, Confusing, Longwinded, Unconvincing, Fascinating, Ingenious, Courageous, Funny, Informative and Inspiring.
MATCH (r:Rating {name: "Funny"})<-[e:HasRating]-(m:Talk)
RETURN m.name, e.user_count
ORDER BY e.user_count DESC
LIMIT 20;
6) Find inspiring talks and their speakers from the field of technology:
MATCH (n:Talk)-[:HasTag]->(m:Tag {name: "technology"})
MATCH (n)-[r:HasRating]->(p:Rating {name: "Inspiring"})
MATCH (n)<-[:Gave]-(s:Speaker)
WHERE r.user_count > 1000
RETURN n.title, s.name, r.user_count
ORDER BY r.user_count DESC;
7) Now let's see one real-world example — how to make a real-time recommendation. If you've just watched a talk from a certain speaker (e.g. Hans Rosling) you might be interested in finding more talks from the same speaker on a similar topic:
MATCH (n:Speaker {name: "Hans Rosling"})-[:Gave]->(m:Talk)
MATCH (t:Talk {title: "New insights on poverty"})
-[:HasTag]->(tag:Tag)<-[:HasTag]-(m)
WITH *
ORDER BY tag.name
RETURN m.title AS title, collect(tag.name) AS names, count(tag) AS tagCount
ORDER BY tagCount DESC, title;
The following few queries are focused on extracting information about TED events.
8) Find how many talks were given per event:
MATCH (n:Event)<-[:InEvent]-(t:Talk)
RETURN n.name AS event, count(t) AS talksCount
ORDER BY talksCount DESC, event
LIMIT 20;
9) Find the most popular tags in the specific event:
MATCH (n:Event {name:"TED2006"})<-[:InEvent]-(t:Talk)-[:HasTag]->(tag:Tag)
RETURN tag.name AS tag, count(t) AS talksCount
ORDER BY talksCount DESC, tag
LIMIT 20;
10) Discover which speakers participated in more than 2 events:
MATCH (n:Speaker)-[:Gave]->(t:Talk)-[:InEvent]->(e:Event)
WITH n, count(e) AS eventsCount
WHERE eventsCount > 2
RETURN n.name AS speaker, eventsCount
ORDER BY eventsCount DESC, speaker;
11) For each speaker search for other speakers that participated in same events:
MATCH (n:Speaker)-[:Gave]->()-[:InEvent]->(e:Event)<-[:InEvent]-()<-[:Gave]-(m:Speaker)
WHERE n.name != m.name
WITH DISTINCT n, m
ORDER BY m.name
RETURN n.name AS speaker, collect(m.name) AS others
ORDER BY speaker;