Import Protobuf data
Similar to Apache Avro,
Protobuf is a method of
serializing structured data. A message format is defined in a .proto file, and
you can generate code from it in many languages, including Java, Python, C++,
C#, Go, and Ruby. Unlike Avro, Protobuf does not serialize schema with the
message. In order to deserialize the message, you need the schema in the
consumer. A benefit of working with Protobuf is the option to define multiple
messages in one .proto file.
Example
Let's assume we have the following schemas coming out of their respective topics
pbStreamProfile, pbStreamCompany, pbStreamWorksAt:
syntax = "proto3";
message Person {
string name = 1;
int64 age = 2;
string email = 3;
string address = 4;
}
message Company {
string name = 1;
string address = 2;
}
message WorksAt {
string name = 1;
string company = 2;
}
These schemas translate into the .proto file.
Before making your transformation script, it is necessary to generate
code
from .proto file.
We can use the schemas to build the following graph:
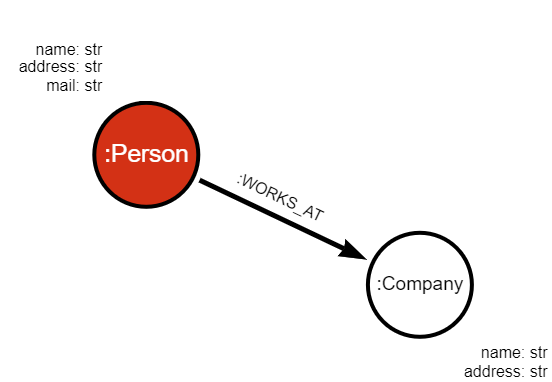
Deserialization
Data received by the Memgraph consumer is a byte array and needs to be deserialized. The following method will help you deserialize your data with the help of Confluent Kafka:
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.protobuf import ProtobufDeserializer
import person_pb2 # proto file compiled into Python module
def process_record_protobuf(record: bytes, message_type: obj) -> dict:
deserializer = ProtobufDeserializer(message_type)
return deserializer(record, None)
message_type corresponds to the message defined in .proto file. This method
should be added to the transformation module.
Transformation modules
Before consuming data from a stream, we need to implement transformation modules that will produce queries. In order to create a transformation module, you need to:
- Create a Python module
- Save it into the Memgraph's query-modules directory (default:
/usr/lib/memgraph/query_modules) - Load it into Memgraph either on startup (automatically) or by running the
CALL mg.load_allquery
Additionally, the compiled file should also be saved in the query modules directory.
Example of the profile_transformation module:
@mgp.transformation
def profile_transformation(messages: mgp.Messages) -> mgp.Record(query = str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message_pb = messages.message_at(i)
msg_value = message_pb.payload()
message = process_record_protobuf(msg_value, person_pb2.Person)
result_queries.append(mgp.Record (
query=f'CREATE (p: Person {{ name: "{message.name}", age: ToInteger({message.age}), address: "{message.address}", email:"{message.email}" }});' ,
parameters=None
))
return result_queries
Creating the streams
To import data into Memgraph, we need to create a stream for each topic and apply our transformation module on incoming data:
CREATE STREAM pbStreamProfile TOPICS pb-stream-profile TRANSFORM protobuf_transform.profile_transformation;
CREATE STREAM pbStreamCompany TOPICS pb-stream-company TRANSFORM protobuf_transform.company_transformation;
CREATE STREAM pbStreamWorksAt TOPICS pb-stream-worksat TRANSFORM protobuf_transform.works_at_transformation;
To start the streams, type the following query:
START ALL STREAMS;
Run the following query to check if all the streams were started correctly:
SHOW STREAMS;
You can also check the node counter in Memgraph Lab (Overview tab) to see if new nodes and relationships are arriving.
Next steps
Check out the example-streaming-app on GitHub to see how Memgraph can be connected to a Kafka stream.